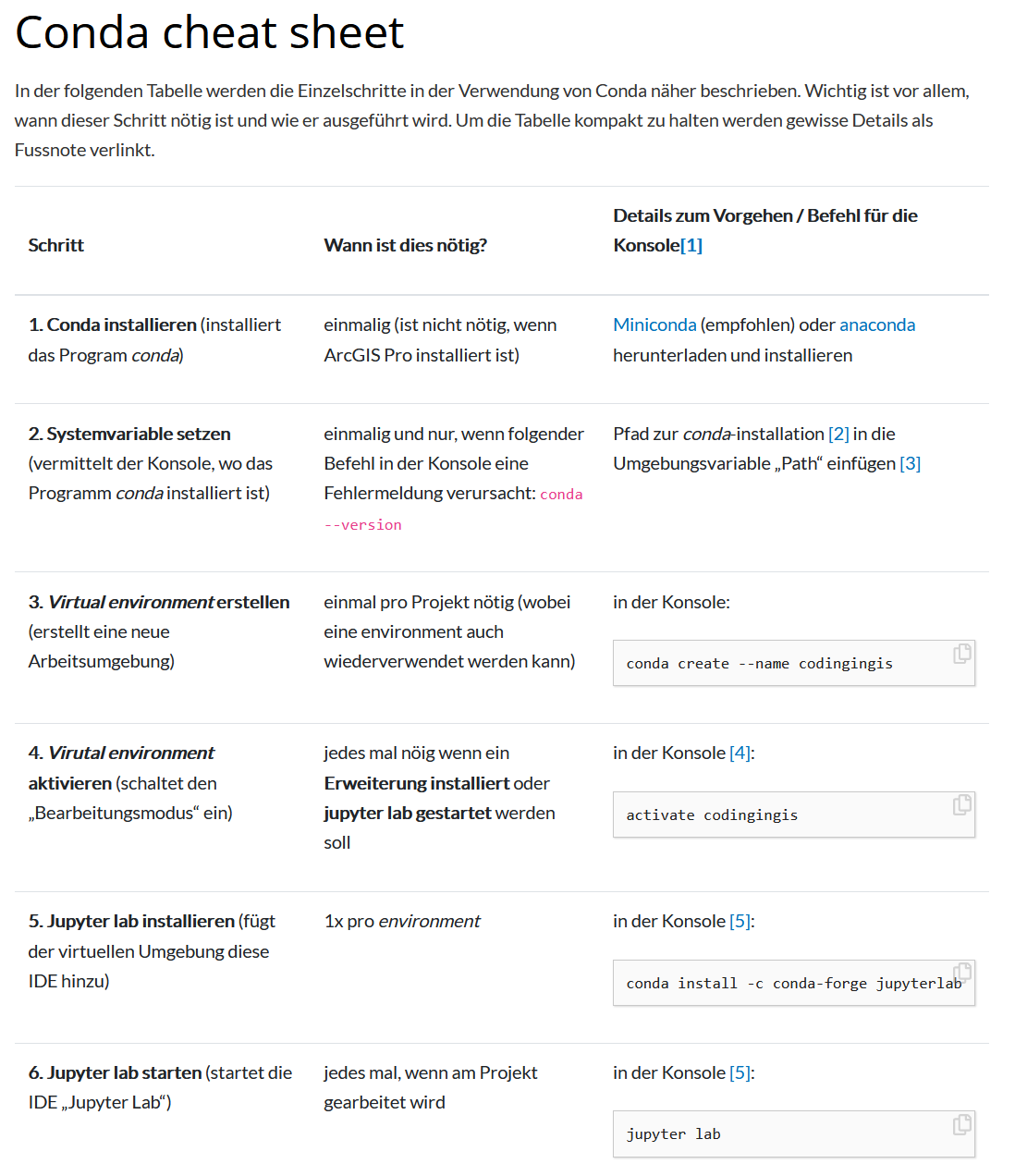
Zeitplan
| Uhrzeit | ΔT | Thema |
|---|---|---|
| 13.00 - 13.30 | 30 | Module, Virtual Environments und Conda |
| 13.30 - 13.45 | 15 | Kapitel Conda, JupyterLab |
| 13.50 - 14.35 | 45 | Aufgabe 5 & 6 |
| 14:50 - 15.35 | 45 | Aufgabe 7 & 8 |
| 15.50 - 16.35 | 45 | Aufgabe 8 & 9 |
Lernziele
- Ihr wisst was Python Modules / Libraries sind und wie man sie installiert
- Ihr kennt das Konzept von Conda Environments und könnt diese nutzen
- Ihr wisst was eine Working Directory ist und könnt diese abfragen und setzen
- Ihr wisst wie man in Python Funktionen nutzt und könnt diese gezielt anwenden
- Ihr wisst wie man in Python If/Else Konditionen nutzt und könnt diese gezielt anwenden
- Primitive Datentypen kennengelernt
- Komplexe Datentypen kennengelernt
- Boolean
- String
- Integer
- Float
- List
- Dict
- DataFrame
- Wie verhalten sich komplexe Datentypen zu den primitiven Datentypen?
- Von Lists, Dicts und DataFrames: Welcher Datentyp tanzt aus der Reihe (und warum)?

Conda
- Installation von Python Modules / Libraries
- Verwalten von Virtual Environments


mit pandas?
Wie nutzt man Conda ?
- Schritt 1: Miniconda herunterladen und installieren
- Schritt 2: Systemvariable setzen (falls nötig)
- Schritt 3: Eine Virtual Environment erstellen
- Schritt 4: Die Virtual Environment aktivieren
- Schritt 5: Modul installieren
Schritt 1: Miniconda herunterladen und installieren
- docs.conda.io/projects/miniconda
- CLI Software (kein GUI)
- wird mit ArcGIS Pro mitgeliefert
- Verwechslungsgefahr: Anaconda
Schritt 2: Systemvariable setzen (falls nötig)
- Conda wird von der Konsole bedient
- Die Konsole sucht in verschiedenen Ordnern nach der Software Conda
- Die Liste dieser Ordner ist in den Umgebungvariablen festgehalten
- Falls nötig müssen wir den Conda-Pfad ausfindig machen und dieser Liste hinzufügen
- Wenn ihr auf Windows arbeitet und ArcGIS installiert habt, ist conda vermutlich hier installiert:
C:\Program Files\ArcGIS\Pro\bin\Python\Scripts
Zwischenschritt: Testen ob conda funktioniert
# Test, ob Conda funktioniert:
(arcgispro-py3) C:\Program Files\ArcGIS\Pro\bin\Python\envs\arcgispro-py3>conda --version
# Wenn eine Versionsnummer erscheint: 👍
conda 22.9.0
# notiert euch diese Nummer für später
Schritt 3: Eine Virtual Environment erstellen
(Falls du letzte Woche bereits einen Environment namens geopython erstellt hast, wähle einen anderen Namen)
conda
create
--name
geopython
- Ruft das Programm
condaauf - Ruft den Befehl
createvoncondaauf - Kündigt den Namen der neuen Umgebung an
- Bestimmt der Name der neuen Umgebung (beliebig)
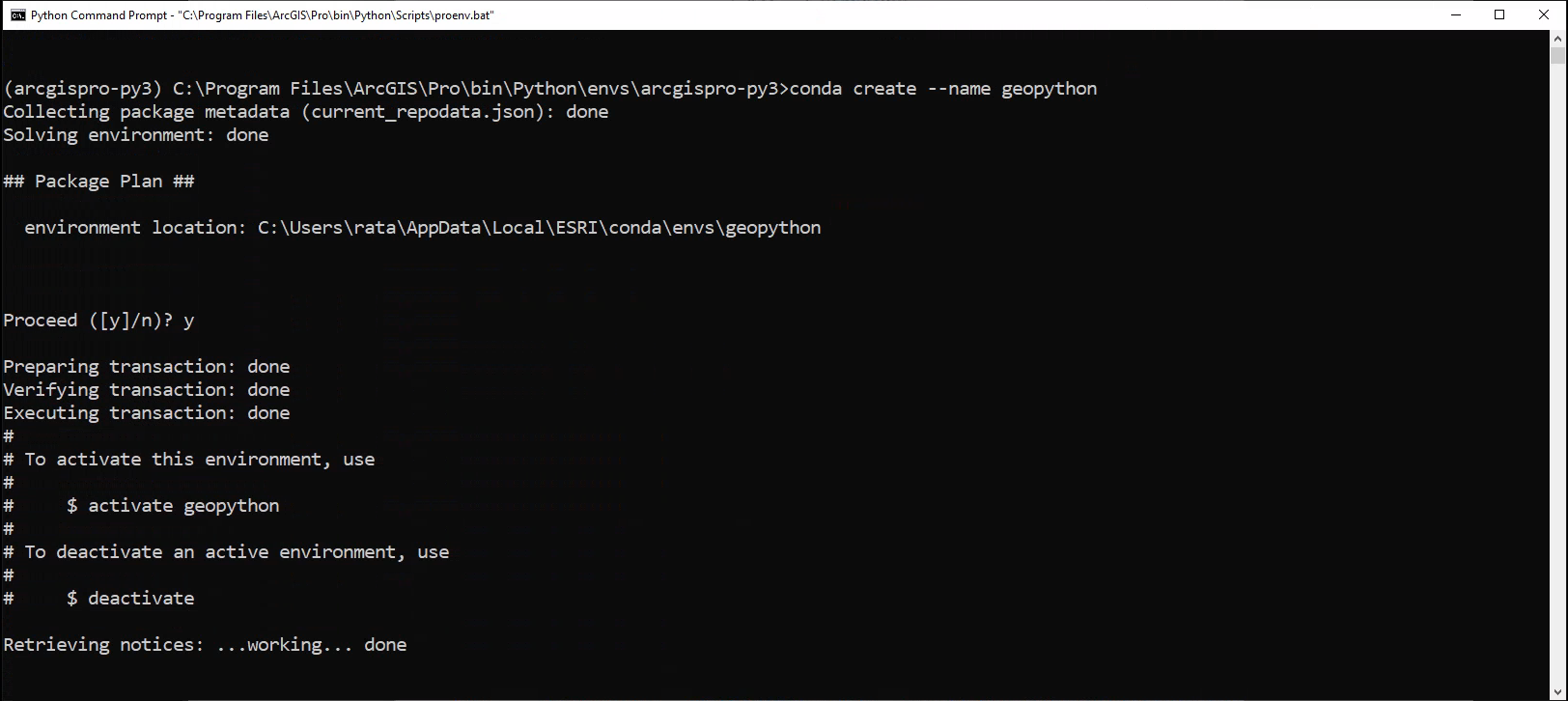 Speicherort:
Speicherort: C:\Users\rata\AppData\Local\ESRI\conda\envs mit Y+Enter bestätigen
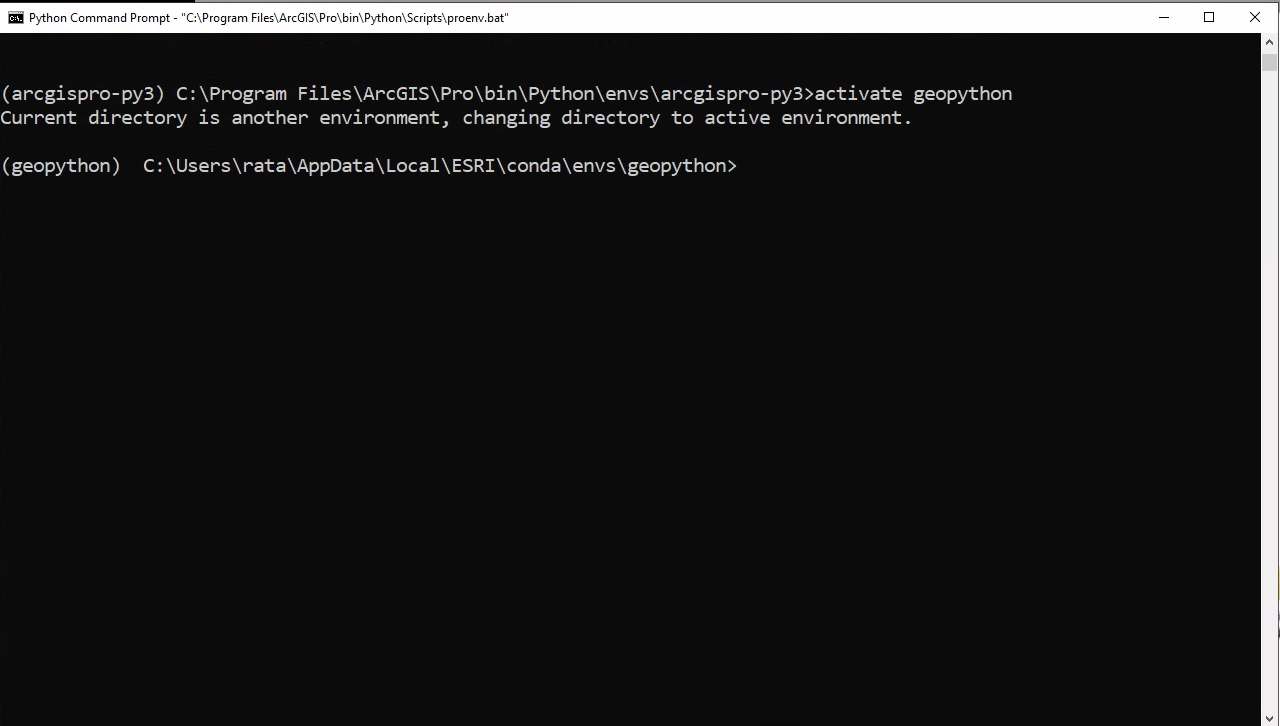
Schritt 4: Environment aktivieren
# Conda version > 4.6
conda activate geopython
# Conda version <= 4.6
activate geopython
conda activate geopython
# Conda version <= 4.6
activate geopython
Aktiviert die Environment geopython
Schritt 5: Modul installieren
conda
install
-c
conda-forge
pandas
- Ruft das Programm
condaauf - Ruft den Befehl
installvoncondaauf - Kündigt der Name des channels an (von wo soll das Modul installiert werden?)
- Ist der Name des channels
- Ist der Name des Python Moduls
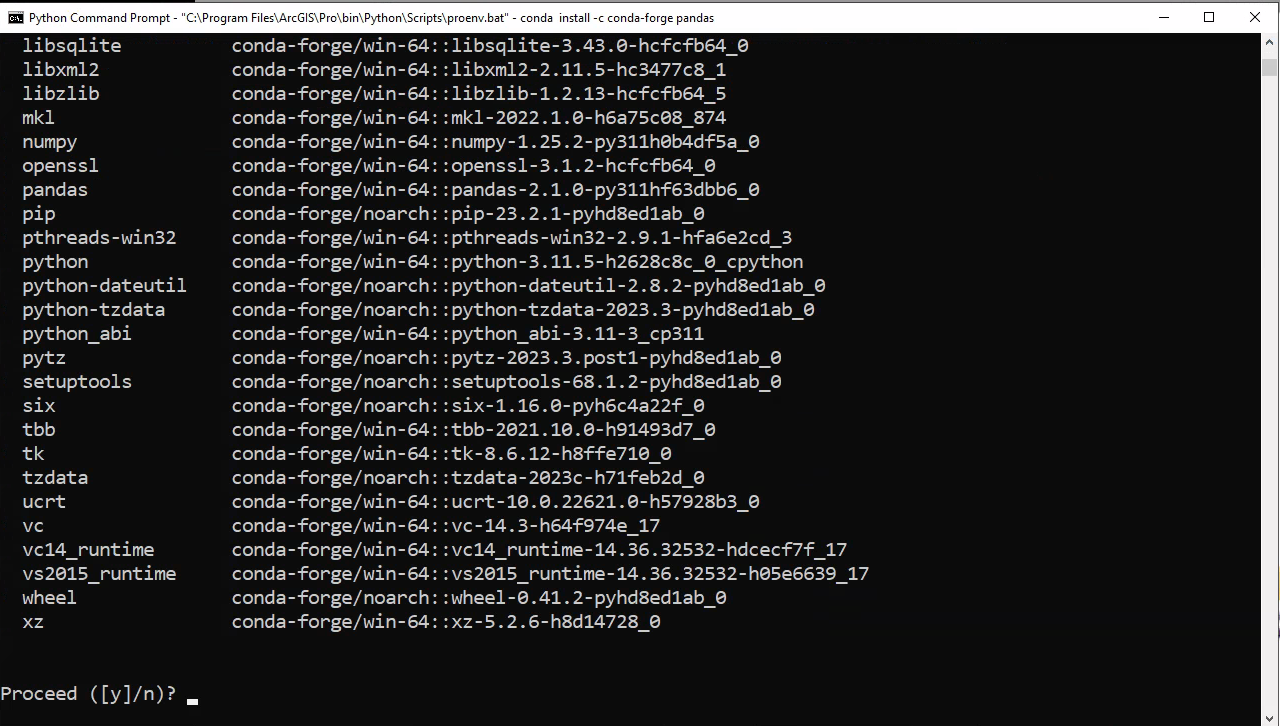
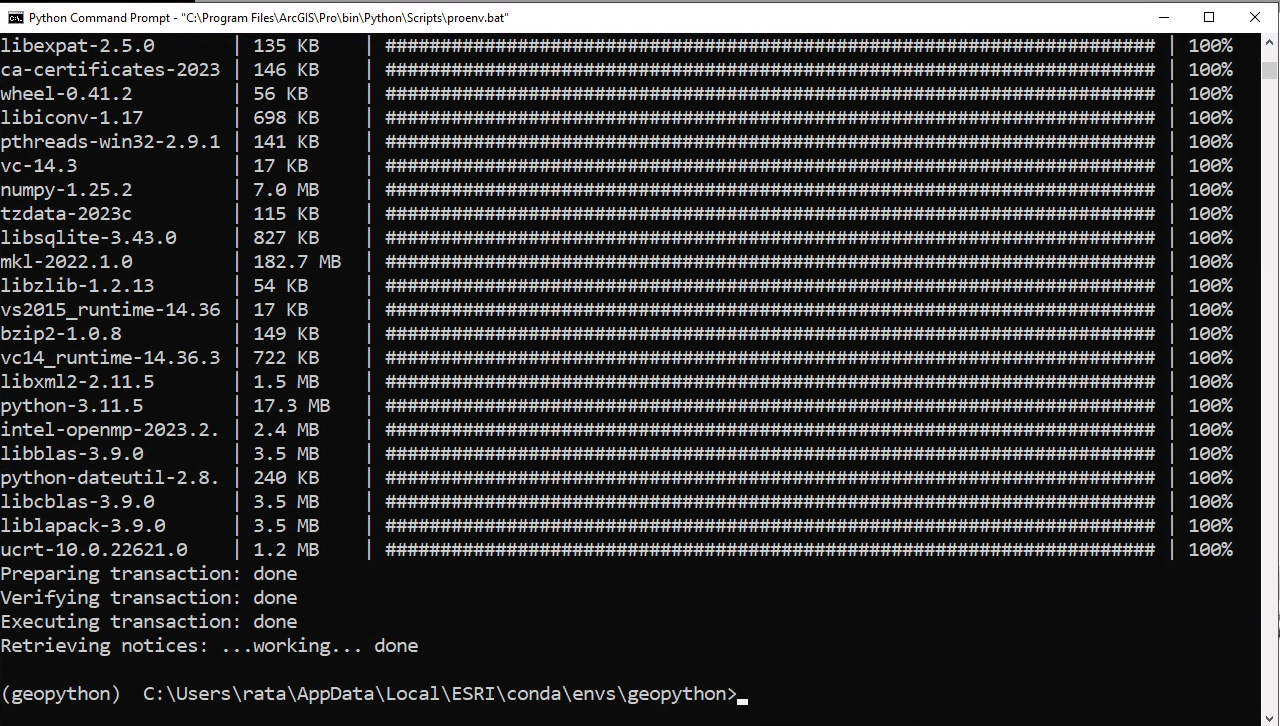
Für Programmieren II brauchen wir nachstehende Module von conda-forge:
- jupyterlab
- pandas
jupyterlab installiert ist, könnt
ihr die Anwendung mit folgendem Befehl in die
Konsole starten: jupyter lab
Warum verbringen wir so viel Zeit mit conda?
- Wichtige Basis für Python
- Wird oft vorausgesetzt
- Wird meist unzureichend erklärt
- Verbindet zwei Welten


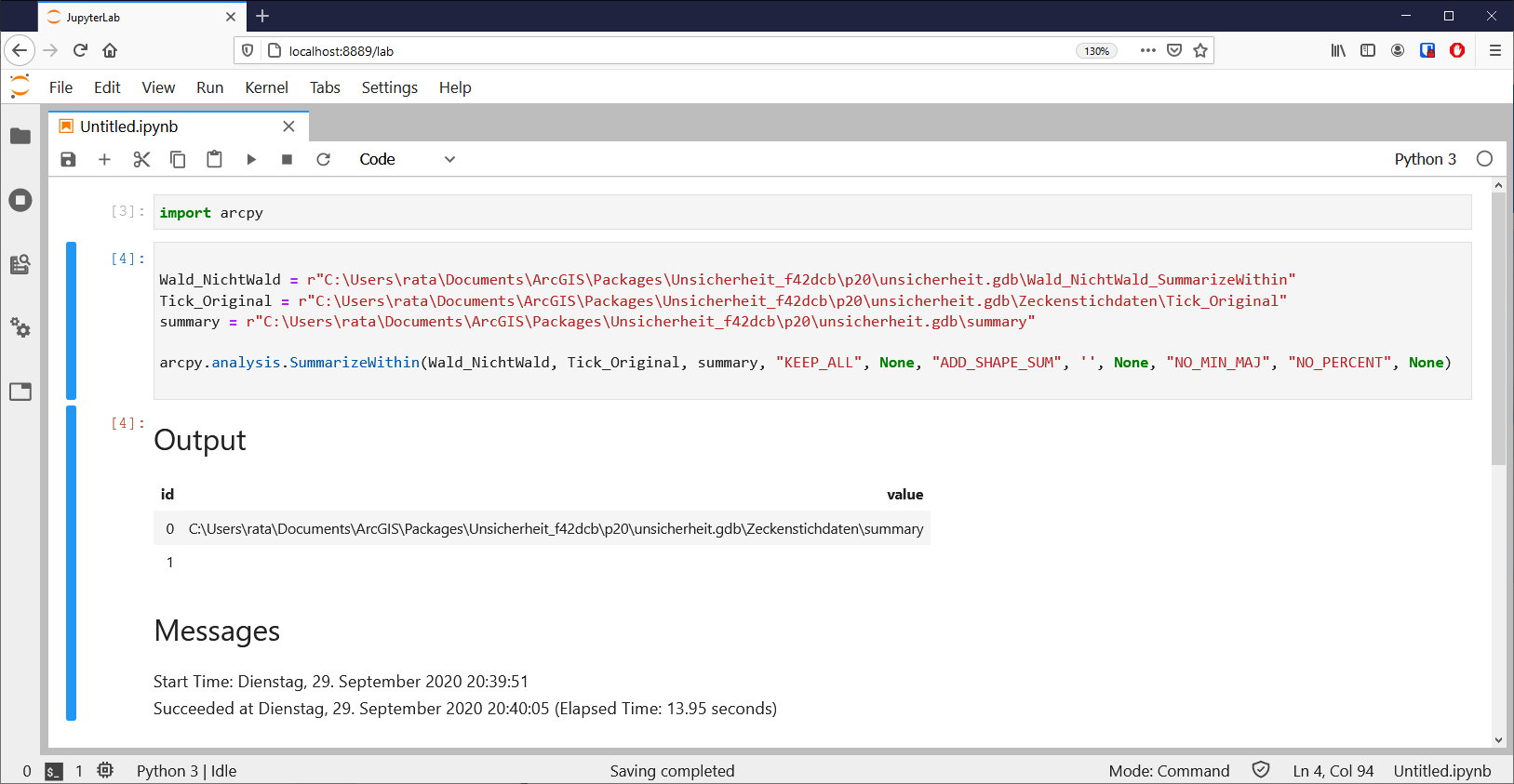
arcpy.analysis.SummarizeWithin("Wald_NichtWald",
"Tick_Original",
r"C:\unsicherheit.gdb\summary",
"KEEP_ALL",
None,
"ADD_SHAPE_SUM",
'',
None,
"NO_MIN_MAJ",
"NO_PERCENT",
None
)


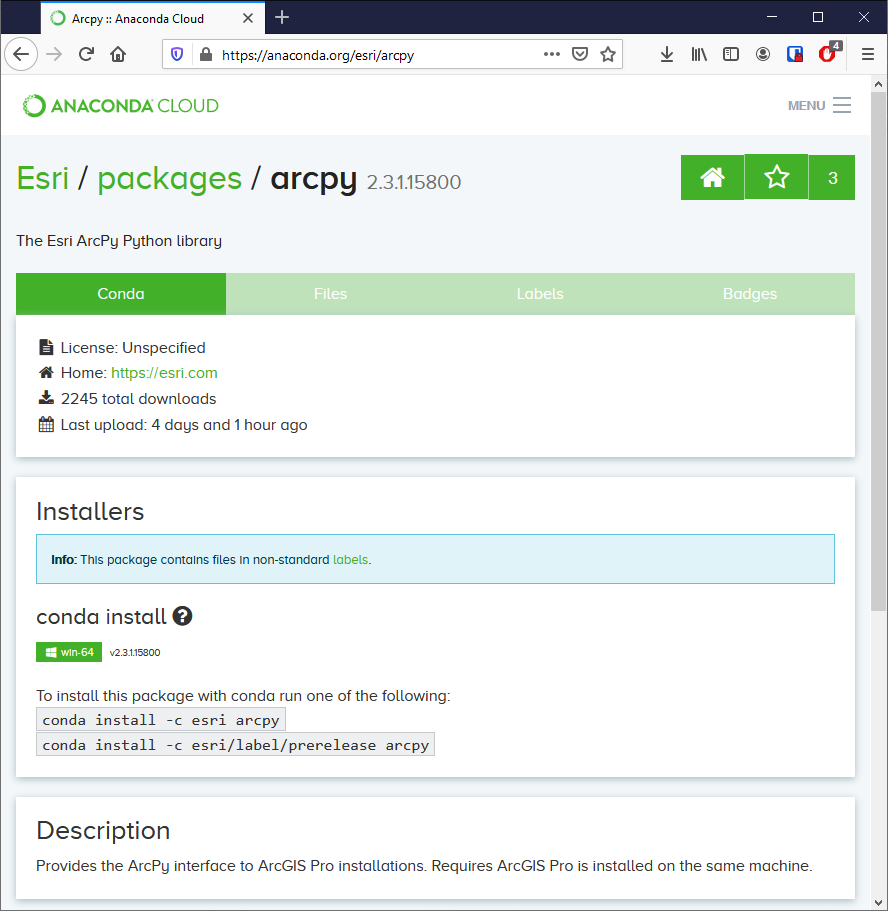
conda install -c esri arcpy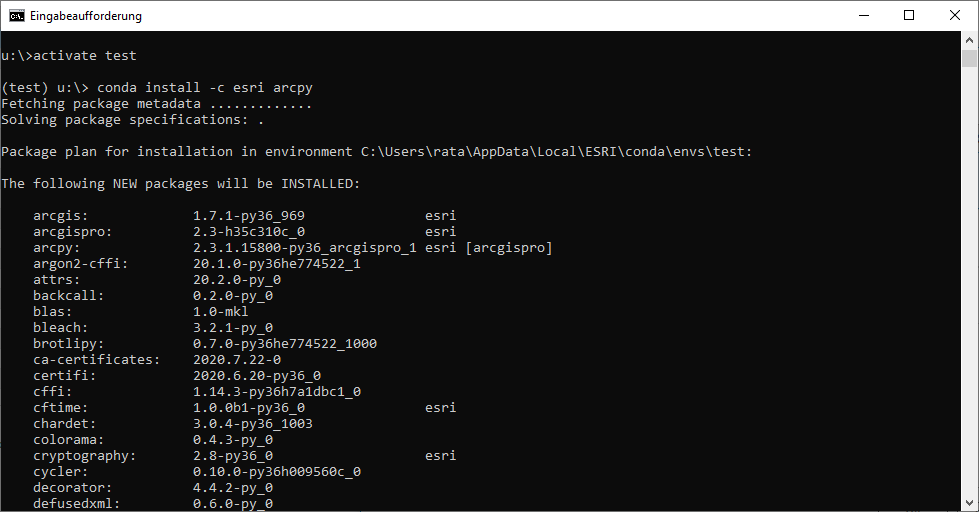

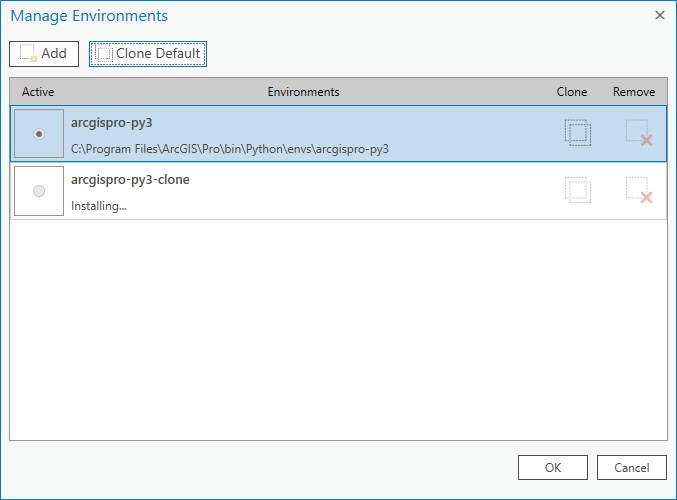
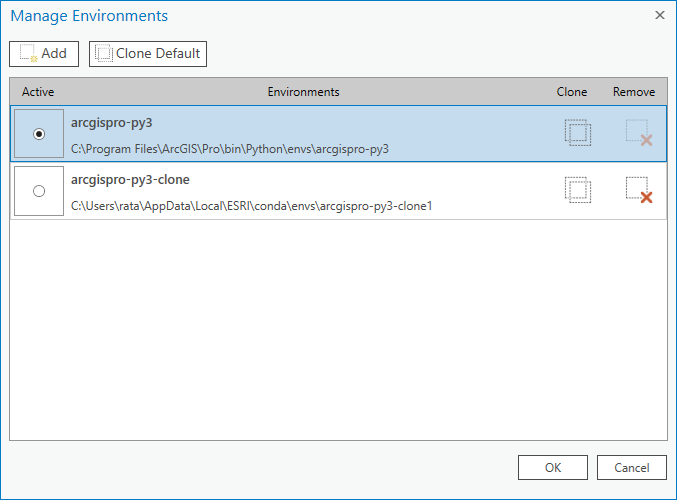
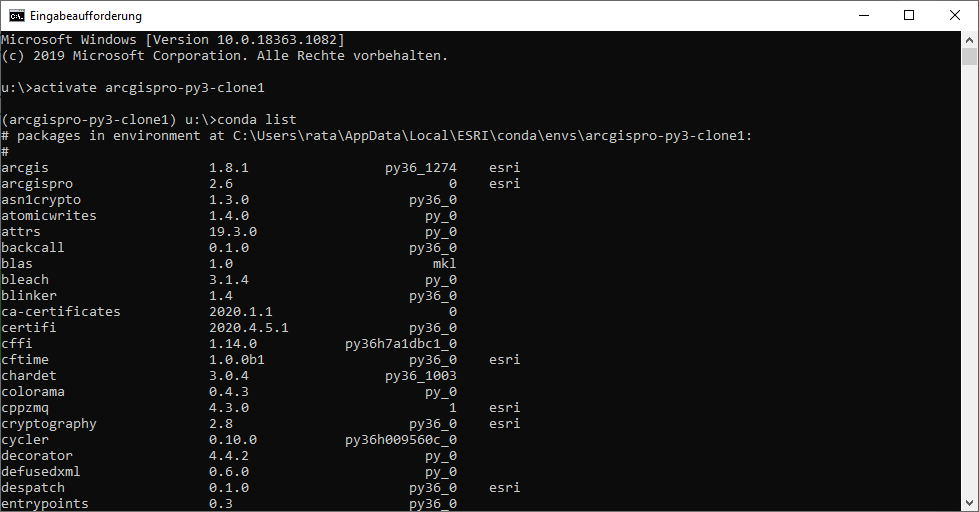
Heute lernen wir:
- Erstellen und verwenden von functions
- Erstellen und verwenden von If / Else Konditionen
- Arbeiten mit Zufallszahlen-Generatoren (um die Zeckenstiche Zufällig zu verschieben)
- Arbeiten mit functions in Data.Frames
Keep your code tidy!
import padnas as pd
pd.read_csv("zeckenstiche.csv")
import pandas as pd
zeckenstiche.head()
import os
zeckenstiche = pd.read_csv("Zeckenstiche.txt")
zeckenstiche = pd.read_csv("zeckenstiche.csv")
import padnas as pd
import pandas as pd
import os
pd.read_csv("zeckenstiche.csv")
zeckenstiche.head()
zeckenstiche = pd.read_csv("Zeckenstiche.txt")
zeckenstiche = pd.read_csv("zeckenstiche.csv")
import pandas as pd
import os
#pd.read_csv("zeckenstiche.csv")
zeckenstiche.head()
zeckenstiche = pd.read_csv("zeckenstiche.csv")
import pandas as pd
import os
#pd.read_csv("zeckenstiche.csv")
zeckenstiche = pd.read_csv("zeckenstiche.csv")
zeckenstiche.head()