Manche mag das jetzt überraschen, andere haben es vielleicht schon gemerkt: Mit GIS hatte unseres bisheriges Wirken in Python eigentlich wenig zu tun. Unsere Zeckenstiche haben zwar x/y-Koordinaten, aber diese haben wir bisher gleich behandlet wie alle anderen Spalten.
Anders gesagt: Wir wissen ja, dass mit den Spalten x und y Koordinaten in der Schweiz gemeint sind, Python hingegen wusste das bisher (noch) nicht. Der konkrete Raumbezug fehlt also noch und das wird irgendwann problematisch: Denn bald wollen wir für jeden simulierten Zeckenstich ermitteln, ob er sich im Wald befindet oder nicht. Das ist eine explizit räumliche Abfrage, welche nur mit explizit räumlichen Geodaten beantwortet werden kann.
Was wir später mit den simulierten Zeckenstiche machen wollen, spielen wir an dieser Stelle mit den original Zeckenstichmeldungen (zeckenstiche.csv, siehe Tabelle 1) durch.
# Unsere Zeckenstiche hatten wir auf folgende Weise importiert:import pandas as pdzeckenstiche = pd.read_csv("data/zeckenstiche.csv")zeckenstiche
ID
accuracy
x
y
0
2550
439.128951
2681116
1250648
1
10437
301.748542
2681092
1250672
2
9174
301.748542
2681128
1250683
3
8773
301.748542
2681111
1250683
4
2764
301.748529
2681131
1250692
5
2513
301.748529
2681171
1250711
6
9185
301.748542
2681107
1250712
7
28521
301.748542
2681124
1250720
8
26745
301.748542
2681117
1250725
9
27391
301.748542
2681138
1250725
DataFrames > GeoDataFrames
Glücklicherweise können wir unsere Zeckenstich-Dataframe mit nur einem Zusatzmodul und wenigen Zeilen Code in eine räumlicheDataFrame konvertieren. Mit dem Modul geopandas erstellen wir aus unserer pandas DataFrame eine geopandas GeoDataFrame. Mit dieser Erweiterung erhält die DataFrame:
geometry: eine Zusatzspalte geometry mit der Geometrie als räumliches Objekt und
crs: ein Attribut crs, welches das Koordinatenbezugssystem der Geometriespalte enthält.
Beide Bestandteile müssen wir bei der Erstellung der GeoDataFrame festlegen. Nachstehend seht ihr, wie ihr dies bei den Zeckenstichen machen könnt. Was diese Bestandteile genau bedeuten, seht ihr in Aufbau von GeoDataFrames (geometry) und Koordinatenbezugssystem (crs).
import geopandas as gpdgeom = gpd.points_from_xy( zeckenstiche['x'], # ↘ zeckenstiche['y'] # → die Geometrie Spalte ) zeckenstiche_gpd = gpd.GeoDataFrame( zeckenstiche, # die DataFrame ("Attributtabelle") geometry = geom, # crs =2056# das Koordinatenbezugssystem (EPSG Code) )
Nun sehen wir, dass die neue geometry-Spalte die Punkt-Geometrie enthält.
zeckenstiche_gpd
ID
accuracy
x
y
geometry
0
2550
439.128951
2681116
1250648
POINT (2681116 1250648)
1
10437
301.748542
2681092
1250672
POINT (2681092 1250672)
2
9174
301.748542
2681128
1250683
POINT (2681128 1250683)
3
8773
301.748542
2681111
1250683
POINT (2681111 1250683)
4
2764
301.748529
2681131
1250692
POINT (2681131 1250692)
5
2513
301.748529
2681171
1250711
POINT (2681171 1250711)
6
9185
301.748542
2681107
1250712
POINT (2681107 1250712)
7
28521
301.748542
2681124
1250720
POINT (2681124 1250720)
8
26745
301.748542
2681117
1250725
POINT (2681117 1250725)
9
27391
301.748542
2681138
1250725
POINT (2681138 1250725)
Zudem hat die GeoDataFrame nun ein Attribut crs, wo das Koordinatenbezugssystem gespeichert ist.
zeckenstiche_gpd.crs.name
'CH1903+ / LV95'
Aufbau von GeoDataFrames
Mit geometry = haben wir die Geometriespalte der GeoDataFrame festgelegt. Bei unseren Zeckenstichdaten ist die Geometrie sehr simpel: Sie besteht aus Punkt-Objekte die sich wiederum aus den x- und y-Koordinaten zusammensetzen. Um x/y-Koordinaten in Punktgeometrien zu konvertieren, gibt es in Geopandas die Funktion points_from_xy. Diese verwende ich im obigen Code, um die Punkt-Objekte zu erstellen.
An dieser Stelle ist es wichtig, die drei Hierarchiestufen von GeoDataFrames zu kären. Von “unten” nach “oben” erläutert gibt es folgende Stufen:
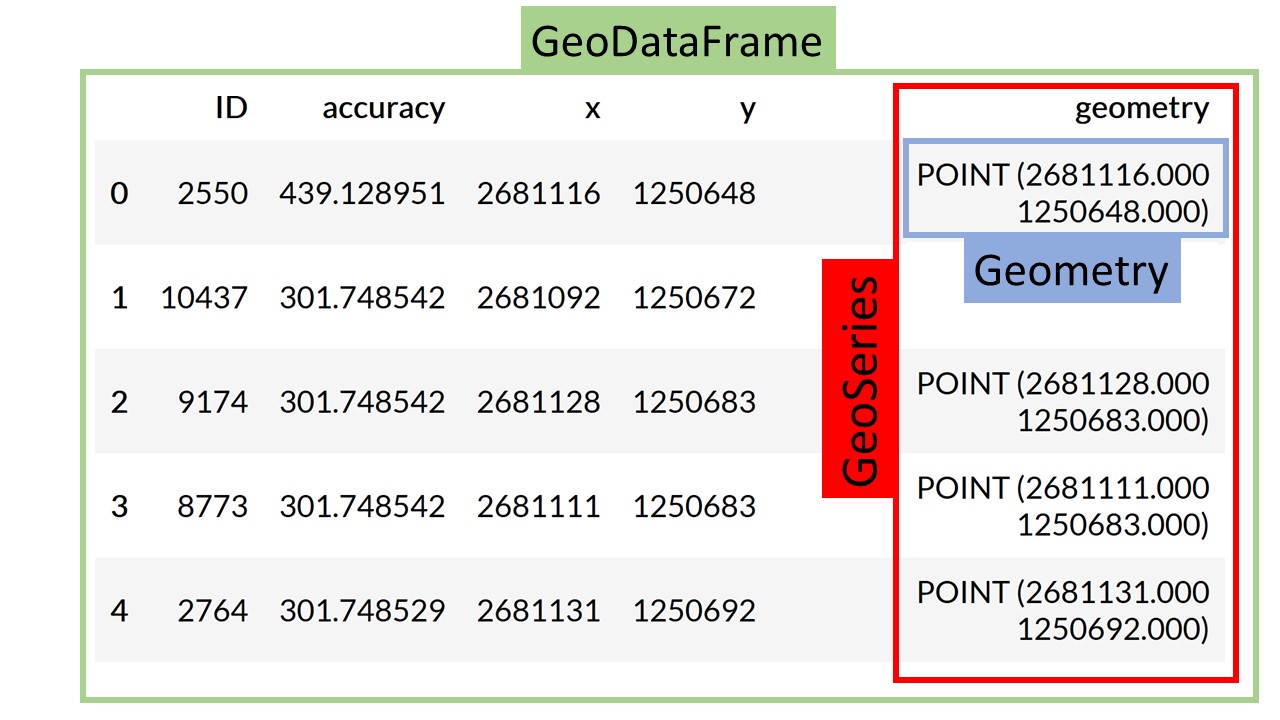
GeoSeries: Eine vielzahl an Geometries, typischerweise eine Spalte einer GeoDataFrame namens (geometry)
GeoDataFrame: Eine Tabelle, welche über eine Geometrie-Spalte (GeoSeries) verfügt
Abbildung 44.1: Die drei Hierarchien in Geopandas: Eine GeoDataFrame verfügt immer über eine Geometrie-Spalte, welche sich eine GeoSeries nennt. Diese wiederum besteht aus Einzelgeometrien, sogenannten Geometries.
Koordinatenbezugssystem
Mit crs = wird das Koordinatenbezugssystem (engl. Coordinate Reference System) unseres Datensatzes festgelegt. Das Koordinatenbezugssystem gibt unseren x/y-Zahlenwerten einen konkreten Raumbezug auf dem Planeten und macht aus ihnen Koordiaten in der Schweiz. Wie lautet aber das “Koordinatenbezugssystem” unserer Daten?
Im Prinzip weiss diese Information nur derjenige, der die Daten erstellt hat. Man man das Koordinatensytem aber auch anhand der Koordinaten erahnen: Es handelt sich in unserem Fall um Werte im Bereich von 2’600’000 auf der einen und 1’200’000 auf der anderen Achse. Da wir wissen, dass die Daten aus der Schweiz stammen, kann man mit etwas Erfahrung sagen, dass es sich um Daten im neuen Schweizer Koordinatenbezugssystem CH1903+ / LV95 handeln muss. Der EPSG Code dieses Koordinatenbezugssystems lautet 2056 und diesen Code können wir in der Funktion gpd.GeoDataFrame nutzen, um das korrekte Koordinatenbezugssystem zuzuweisen.
# Das Attribut `crs` wurde aufgrund vom EPSG Code richtig erkannt:zeckenstiche_gpd.crs.name
'CH1903+ / LV95'
Diese CRS Information erlaubt uns auch, mit einer Zeile Code eine Webmap unserer Zeckenstiche zu machen. Versucht es aus!
zeckenstiche_gpd.explore()
Make this Notebook Trusted to load map: File -> Trust Notebook
Geodatenformate
Das Einlesen von CSV und die Konvertierung von DataFrame zu GeoDataFrame hat bei den Zeckenstichen zwar gut funktioniert, es ist aber auch etwas umständlich, jedes Mal die geometry Spalte und das crs zu setzen. CSVs eignen sich nicht besonders gut für das speichern von Geodaten, insbesonders wenn die Daten komplexer sind (Linien, Polygone..)). Deshalb gibt es auch spezifische Datenformate, in den Geodaten gespeichert werden können. Bei diesen Datenformaten werden geometry und crs automatisch abgespeichert.
Ihr seid im Studium mit solchen Datenformate bereits in Kontakt gekommen, sicher kennt ihr ESRI’s File Geodatabases/Feature Classes sowie Shapefiles. Dies sind häufig genutzte Formate, aber leider nicht offen, und gerade Shapefiles haben viele Tücken (siehe switchfromshapefile.org). Es gibt dafür ganz tolle Alternativen, beispielsweise Geopackages (nicht zu verwechseln mit ArcGIS Pro Packages!). Mit nachstehendem Befehl können wir zeckenstiche_gpd als Geopackage abspeichern.
zeckenstiche_gpd.to_file("data/zeckenstiche.gpkg", driver ="GPKG") # Wer UNBEDINGT ein shapefile abspeichern will, # kann ".gpkg" mit ".shp" ersetzen# (-_-)
Das File “zeckenstiche.gpkg” befindet sich nun in meiner Working Directory und ich kann sie mit gpd.read_file("data/zeckenstiche.gpkg") wieder einlesen. Im Unterschied zu vorher musst ich nun geometry und crs nicht mehr zuweisen, diese sind beim Schreiben des Geopackage abgespeichert worden. Das Geopackage kann ich nun auch mit ArcGIS / QGIS öffnen, wenn ich die Punkte interaktiv explorieren möchte.
Im Block “Datenqualität und Unsicherheit” habt ihr mit dem Wald-Datensatz gearbeitet. Ich habe diesen als Geopackage exportiert (siehe Tabelle 1) und kann ihn wie im nachstehenden Codeblock ersichtlich einlesen und visualisieren.
wald = gpd.read_file("data/wald.gpkg") # <- importiert das File "wald.gpkg"wald
Shape_Area
Wald_text
geometry
0
2.380876e+08
nein
MULTIPOLYGON Z (((2692100 1256542.253 276.942,...
1
7.963237e+07
ja
MULTIPOLYGON Z (((2689962.355 1245335.25 644.5...
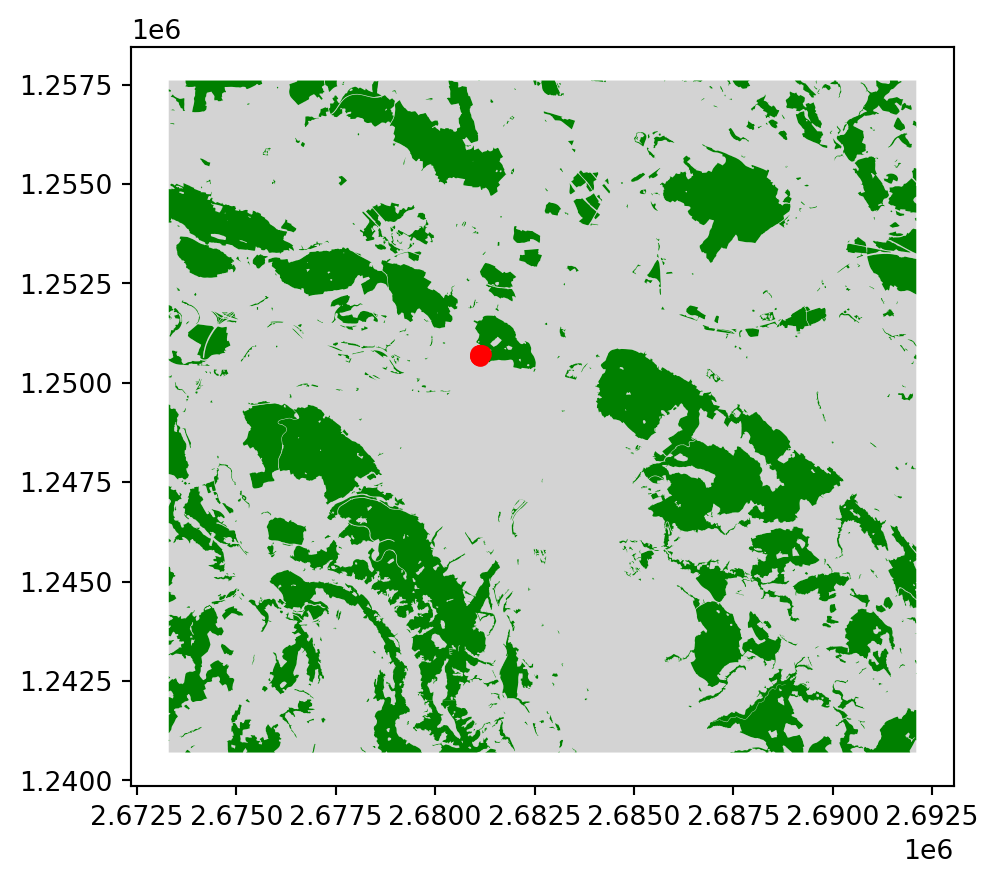
Es handelt sich also um einen Datensatz mit nur zwei Zeilen, aber mehreren Polygonen pro Zeile (das macht es zu einem Multipolygon). Mit plot können wir diesen Datensatz einfach visualisieren und mit den Zeckenstichdaten überlagern.
Hinweis 44.1
Der Unterschied zwischen Point und Multipoint, Linesstring und Multilinestring und Polygon Multipolyon ist folgendermassen: Typischerweise hat jedes Attribut eine Geometrie. Zum Beispiel hat jede Zeckenstichmeldung eine ID, eine Ungenauigkeitsangabe und eben eine Punkgeometrie. Somit handelt es sich bei diesem Datensatz um einen einfach Point Datensatz. Wenn pro Attribut mehrere Geometrien zugewiesen sind handelt es sich um ein Multipoint Objekt.
base = wald.plot(color = ["Lightgrey","Green"])zeckenstiche_gpd.plot(ax = base, color ="red")
Noch einfacher und sogar mit einer Basemap und Zoom-Möglichkeit geht es mit der explore() Methode. Nun wird übrigens auch klar, dass es sich bei unseren 10 Zeckenstichen um sehr dicht beieinanderliegenden Punkte handelt.
base = wald.explore()zeckenstiche_gpd.explore(m = base, color ="red")
Make this Notebook Trusted to load map: File -> Trust Notebook